Traitement des données

Données sources
Plusieurs sources de données sont téléchargées et exploitées:
- Transparence Santé (TS),
- le Répertoire Partagé des Professionnels de Santé (RPPS).
Transparence Santé
Les entreprises déclarent les conventions, avantages et rémunérations:
- Les déclarations correspondant au 1er semestre doivent être transmises au plus tard le 1er septembre.
- Les déclarations correspondant au 2ème semestre doivent être transmises au plus tard le 1er mars de l'année suivante.
À noter que le système permet aussi de déclarer et de faire des corrections au fil de l'eau.
Les déclarations sont ensuite traitées et vérifiées, avant d'être intégrées dans Transparence Santé. Certaines déclarations sont rejetées en erreur, et doivent être corrigées par l'industriel. Ces vérifications cependant sont trop laxistes et les équipes d'Euros For Docs vont donc être amenées à corriger les données. In fine, toutes les déclarations doivent être mises en ligne au plus tard le 1er octobre pour le premier semestre, et 1er avril de l'année suivante pour le second semestre.
Chaque nuit, un export des données de la base est publiée sur le site data.gouv.fr. Ces données sont téléchargées et intégrées dans la plateforme Euros For Docs.
Le système technique de déclaration par les entreprises a été modifié en 2022, et les déclarations de plus de 5 ans ont commencé à être dépubliées sur le site officiel comme prévu par la réglementation. Euros For Docs intègre les données d'un export antérieur à 2022, de façon à permettre des analyses sur l'ensemble des déclarations depuis la mise en place du dispositif.
RPPS
L'annuaire santé (RPPS) est également téléchargé et nettoyé (essentiellement pour supprimer les doublons).
Il permet d'obtenir des informations fiables sur les professionnels bénéficiaires, notamment les professions, les spécialités des professionnels, ainsi que la structure dans laquelle ils travaillent.
Les données du RPPS peuvent servir à identifier les bénéficiaires voire à corriger les données déclarées.
Nettoyage des données
Chaque nuit, Euros For Docs télécharge, nettoie et enrichi les données des déclarations. Le code informatique utilisé est disponible en open source sur Gitlab.
Le format des données est décrit de manière globale dans ce tableur en ligne. Par rapport aux données brutes, des champs ont été renommés et d'autres champs généraux ont été tranformés en plusieurs champs spécifiques.
Plusieurs tableaux de bords sont disponibles pour évaluer la qualité des données avant et après traitement par Euros For Docs. Ces tableaux se concentrent sur les bénéficiaire, les entreprises déclarantes et enfin les liens d'intérêt eux-mêmes.
raw_declaration
Déclarations d'intêrets
Rattachement des conventions
Les déclarations de rémunérations et d'avantages ont un champ permettant d'indiquer le numéro d'une convention à laquelle elles sont liées. Le remplissage de ce champ est obligatoire pour les rémunérations, et facultatif pour les avantages. Une rémunération doit se faire dans le cadre d'un contrat, tandis qu'un avantage peut être offert sans cadre contractuel. Une convention peut ainsi être associée à 0, 1 ou plusieurs rémunérations et avantages.
Par exemple, si un médecin est payé pour présenter à un congrès, l'industriel pourra déclarer
- une convention ;
- une rémunération ;
- un avantage pour le transport ;
- un ou plusieurs avantages pour l'hospitalité (nuit d'hôtel, repas) ;
- un avantage pour l'inscription au congrès.
Nous utilisons les champs convention_liee, identifiant_unique et entreprise_ts_id pour rapprocher les conventions et les avantages / rémunérations.
Une fois la convention identifiée, son ID est stockée dans le champs convention_ts_id.
Il y a cependant un pourcentage résiduel (3-5%) de rémunérations que nous ne parvenons pas à relier à une convention, pour les années récentes.
Protection contre les doubles comptes
Toutes les rémunérations et avantages indiquent un montant. Les conventions peuvent - ou non - indiquer un montant global, à priori le total des rémunérations et avantages liés.
Ce point est une difficulté majeure dans l'utilisation de la base Transparence-Santé, qui empêche à priori de sommer les montants des conventions avec ceux des rémunérations et avantages, au risque de compter certains montants deux fois.
Pour résoudre ce problème et faciliter l'utilisation des données, Euros For Docs rattache les rémunérations et avantages avec la convention liée.
- 4 nouvelles colonnes indiquent pour chaque convention le nombre et le montant des rémunérations et avantage liés.
- La colonne principale de
montantpour chaque convention est le montant déclaré pour la convention, moins le montant des avantages et rémunérations liés, avec un résultat minimum à zéro.
Ces transformations permettent de sommer les montants des déclarations toutes catégories confondues, sans double compte, à l'exception des erreurs indiquées plus bas.
Lorsque l'on étudie une convention
- Le montant déclaré initialement dans chaque convention est sauvegardé dans une nouvelle colonne (
montant_declare_convention); - Un montant total de la convention est calculé dans une nouvelle colonnne
montant_total_convention, comme le maximum entre le montant déclaré pour la convention, et la somme des montants des rémunérations et avantages liés.
Contrats sans montant
A contrario, certaines conventions ont un montant déclaré nul (ou vide), sans que l'on ne retrouve de rémunération ni d'avantages liés.
On ne peut donc pas connaître le montant de ces conventions, alors qu'il est obligatoire depuis 2017 de déclarer les rémunérations liées aux conventions (cf fin de la partie sur la qualité des données); et rien ne justifie qu'une entreprise déclare des conventions sans montant - fut-il prévisionnel.
Ces conventions sont indentifiées par la valeur True dans la colonne indicatrice montant_masque.
Cette colonne permet de calculer un nombre de contrat sans montant traçable.
Avantages mal rattachés à leur convention
Les avantages pointent souvent vers des conventions dont le numéro n'existe pas dans Transparence-Santé, car l'existence de ces conventions n'est pas vérifiée avant d'intégrer les avantages à la base.
Par conséquent
- le montant de certains avantages est compté en double lorsqu'il est déclaré aussi dans la convention et que le lien est mal renseigné ;
- une parties des conventions sans montant traçable a bien un avantage (donc un montant) déclaré en lien, mais l'erreur de numéro ne permet pas d'identifier ce montant.
À noter que ce problème technique n'existe (presque) pas pour les rémunérations, car l'existence des conventions liées est vérifiée de façon stricte avant d'intégrer les rémunérations à la base.
Normalisation
De nombreux nettoyage de forme sont réalisés sur les information des déclarations :
- motif_lien_interet
- les valeurs de ce champs (pourtant toujours choisi parmi une liste de valeurs!) sont particulièrement hétéroclites. Une harmonisation est donc faite:
- suppression des doubles espaces
- remplacement des apostrophes rondes par des droites
- remplacement des tirets longs par des tirets standards.
- les valeurs de ce champs (pourtant toujours choisi parmi une liste de valeurs!) sont particulièrement hétéroclites. Une harmonisation est donc faite:
- Jusqu'à récemment, les declarations étaient tres mal catégorisés, presque toutes dans la catégorie 'Autre', avec un texte libre. Nous avons catégorisés les valeurs habituelles de ce champ libre pour catégoriser les déclarations. Voir détails de ce mapping ici.
- Les rémunérations ne sont pas catégorisés dans Transparence Santé, dans l'idée elles sont toujours liées a une convention qui, elle, est catégorisée. Nous appliquons la catégorie de la convention liée à la rémunération pour pouvoir faire des statistiques plus facilement.
Entreprises déclarantes
Déduplication
Si vous cherchez "Pfizer" sur transparence-sante.gouv.fr, vous verrez que Pfizer utilise des dizaines de comptes différents pour faire ses déclarations. Chaque entreprise déclarante peut avoir une entreprise "mère" pour représenter les différentes filiales, mais en pratique, toutes les entreprises n'utilisent pas ce système. Nous avons donc regroupé les entreprises manuellement pour présenter les données de manière plus claire. Voir les détails des regroupements manuels ici.
Certaines entreprises utilisent plusieurs comptes mais remplissent néanmois correctement le SIREN. Si ces entreprises ne remplissent pas le champs "mère", il est toujours possible de les relier entre elles grâce à ce siren commun, et donc les dédupliquer. On choisit donc le compte le plus ancien pour devenir la "mère" des autres comptes dupliqués.
Dans le format Transparence Santé, il n'y a que les informations de l'entreprise déclarante, et l'ID de l'entreprise mère.
Or dans presque toutes les cas, l'entreprise mère, si elle existe, est plus pertinente que l'entreprise déclarante.
Nous avons donc ajouté quelques champs, qui se réfèrent à l'entreprise mère si elle existe, sinon à l'entreprise déclarante.
Ces champs sont préfixés par entreprise_.
Les champs originaux, qui se réfèrent à l'entreprise déclarante, sont eux préfixés par declarant_.
Lors de l'étude d'une entreprise, il est alors plus pertinent de travailler avec les champs entreprise_*.
Bénéficiaires
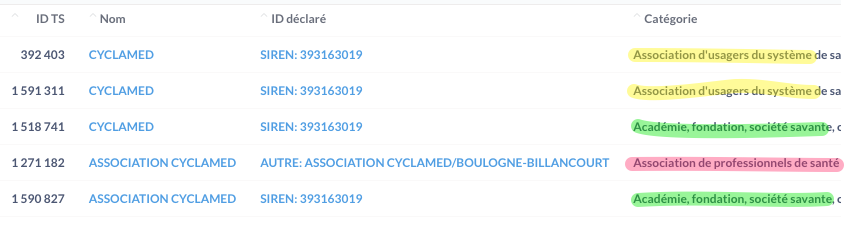
Les entreprises déclarantes ont beaucoup de latitude pour remplir les informations des bénéficiaires. Cela génère de nombreuses incohérences et duplications, parfois même entre les déclarations d'une même entreprise déclarante. Il faut alors un processus plus complexe pour corriger, normaliser et dédupliquer les données. L'image ci dessous montre que même une association aussi connue que Cyclamed peut se voir attribuer des propriétés différentes selon les déclarations.
Euros For Docs se concentre sur plusieurs variables pour identifier et caractériser les bénéficiaires.
- L'identifiant unique dans la base du bénéficiaire. Bien que cet identifiant soit unique dans transparence santé, un bénéficiaire peut se voir attribuer plusieurs identifiants par différentes entreprises déclarantes.
- Le nom (voire prénom) du bénéficiaire est systématiquement disponible mais sous des orthographes non normalisées.
- Le couple de champs (type_code, identifiant) permet aux entreprises déclarantes d'indiquer un identifiant officiel (siren ,rpps, ...) du bénéficiaire. Le premier champs permet d'indiquer le référentiel utilisé et le second l'identifiant du bénéficiaire dans ce référentiel. A travers différentes déclarations, on peut obtenir plusieurs référentiel pour un même bénéficiaire.
- D'autres propriétés du bénéficiaires telles que la profession pour un personnel de santé ou la ville sont aussi renseignées et traitées par Euros For Docs.
Base étendue
La première étape consiste à regrouper pour un identifiant donné toutes les variations des différentes informations fournies par les entreprises déclarantes. Certaines déclarations mentionneront un siren alors que d'autres un numéro d'association. Quelques fois, plusieurs siren différents peuvent être fournis. Cette base de données étendue sert de référence pour le travail de qualité des donnée. L'objectif est de corriger cette base et de remplir les données manquantes pour avoir des informations cohérentes entre toutes les itérations d'un même identifiant unique.
Normalisation des termes
La plupart des champs sont des textes libres et sont donc victimes d'une multiplicité d'orthographes et variations. Par exemple, les noms peuvent être en majuscule ou juste la première lettre. Toute les entreprises déclarantes ne mettent pas les accents.
Plusieurs normalisations de données ont alors lieu sur plusieurs variables.
- Les noms, prénom et professions sont transformées pour suivre les mêmes conventions.
- les numéros siren, adeli, d'association et rpps sont transformés pour retirer les espaces ou caractères inutiles. Les numéros transformés sont alors soumis à l'algorithme de Luhn pour les vérifier.
- les valeurs absurdres (NA, 0, ...) sont retirées.
Réattribution des identifiants
Le format de déclaration des identifiants officiels (siren, rpps) n'est pas très exploitable car un bénéficiaire peut potentiellement avoir plusieurs types d'identifiant. Par exemple, un hopital a un numéro siren et un numéro finess. Pour pouvoir exploiter cette multiplicité d'identifiant, qui pourra à terme nous aider à dédupliquer les bénéficiaires, les identifiants sont restructurés en plusieurs colonne dédiées.
De nombreuses entreprises n'exploitent pas le mécanisme proposé pour renseigner les identifants mais proposent un type 'AUTRE' avec un identifiant consistant en une chaine de caractère contenant potentiellement l'identifiant lui même. Beaucoup d'identifiants "AUTRE" sont de la forme "SIRET : XXXXX". A travers une exploration des données, de multiple schémas similaires ont été identifiés et les identifiants extraits et normalisés. Plusieurs dizaines de milliers de comptes de bénéficiaires sont concernés.
Mise en cohérence
Lorsque les entreprises désignent un bénéficiaire, elle le font à tavers le choix du compte bénéficiaire, tout en pouvant ajouter un identifiant (tel que le RPPS) supplémentaire. Nous avons alors des comptes pour lesquels différentes entreprises ont renseigné des identifiants différents, potentiellement incohérents. Ainsi près de 4000 comptes ont 2 RPPS ou ADELI différents renseignés.
Les comptes de professionnels de santé sont renormalisés en ne gardant qu'un seul identifiant par compte. L'identifiant le plus renseigné est choisi en priorité. En cas d'égalité, on compare les noms des professionnels avec les meme identifiants dans l'annuaire et on garde le plus pertinent. Enfin, si aucun choix n'a pu être fait, l'identifiant qui correspond à la déclaration la plus ancienne est choisi.
Réattribution de RPPS
A ce stade, près de 55% des bénéficiaires (soit près de 600 000 comptes) n'ont aucune identification normalisée. Nous utilisons alors l'annuaire des RPPS pour réattribuer aux bénéficiaires non identifiés leur code RPPS ou ADELI.
Dans un premier temps, on identifiant dans l'annuaire l'ensemble des professionnels de santé qui n'ont pas d'homonymes dans la même profession. Si on identifie un bénéficiaire avec le même nom, prénom et profession, on peut alors lui attribuer le rpps correspondant avec un fort taux de confiance.
Le professions n'étant pas systématiquement remplies, ou de manière non qualitative, nous répétons le processus mais en ne se concentrant que sur le nom et prénom du bénéficiaire. Les couples de nom/prénom qui peuvent être attribués ne doivent pas avoir d'homnymes dans l'annuaire.
Pour éviter de créer de l'incohérence dans les données, les deux étapes précédentes ne sont effectuées que pour les bénéficiaire qui n'ont ni rpps ni adeli. Nous supposons qu'un rpps renseigné est à ce moment valide. Cette réattribution de RPPS permet d'attribuer un rpps ou un adeli à 20% des bénéficiaires.
Déduplication
Une grande part des bénéficiaires physiques possèdent plusieurs comptes dans la base transparence santé. La déduplication consiste à attribuer à chaque bénéficiaire dupliqué un compte d'origine, similaire au compte mère des entreprises.
La déduplication se base sur une représentation des bénéficiaires sous forme de graphe. Les noeuds du graphe sont les comptes de bénéficiaires et les numéros siren, rpps, adeli, ... Chaque compte bénéficiaire est alors lié à un ou plusieurs numéros d'identifiant selon les déclarations des entreprises. On peut alors regrouper des comptes de bénéficiaires reliés entre eux par un ou plusieurs identifiants. Des vérifications de qualité sont ajoutées pour s'assurer de l'unicité de chaque type d'identifiant au sein d'un même groupe.
En plus de lier les bénéficiaires grâces à des identifiants communs, nous ajoutons des liens directs basés l'état civil des bénéficiaires. Nous créons un lien entre deux bénéficiaires s'ils partagent le même nom, prénom et commune. Si un groupe de bénéficiaires possède plus qu'une profession, nous ne créons pas de lien entre eux.
Similairement aux entreprises, les données des bénéficiaires sont réinjectées dans les données de déclaration en privilégiant les données du compte d'origine si celui ci existe. C'est ainsi près de 20% des comptes bénéficiaires qui sont fusionnés à d'autres.